一次不成功的深度学习实践 - 微信跳一跳
|
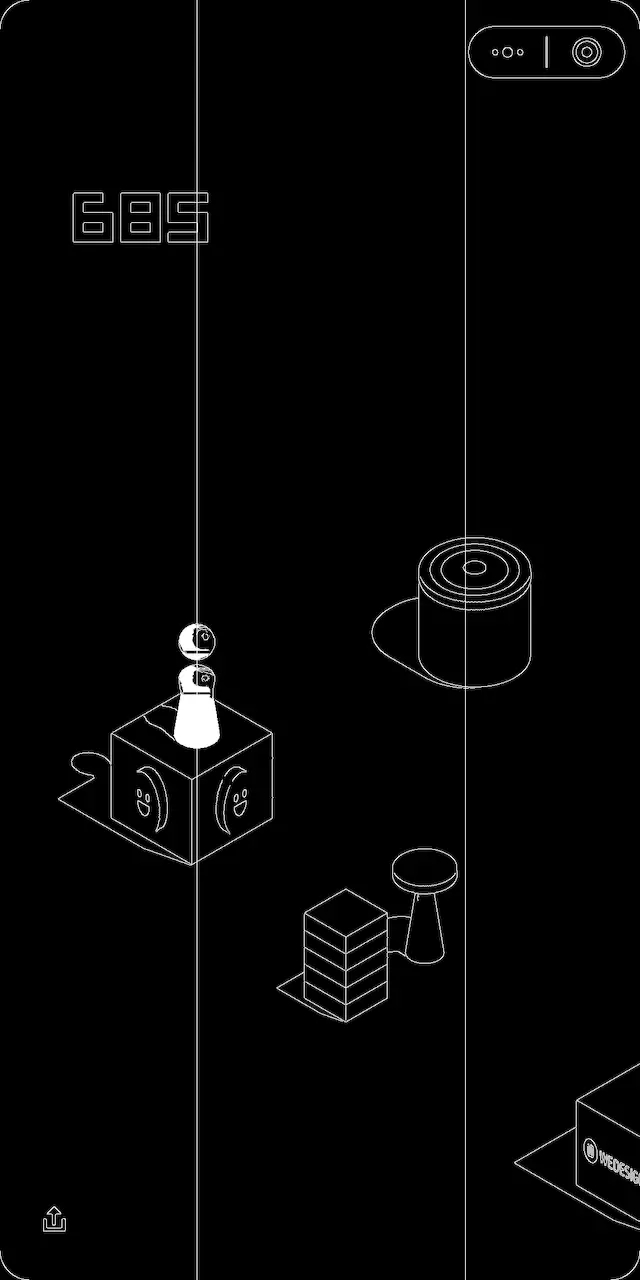
最近微信的跳一跳小程序火了一把,所以前天也更新了微信玩了几盘,最多手动到200左右就不行了。
后来准备用代码写个辅助工具,上Github一查,已经有人做出来了,17年12月29号的项目,不到5天差不多5K的stars,以后还会更多,简直可怕。 github.com/wangshub/we… 具体思路都差不多:
唉,多么可惜,错过了一个好项目。 既然别人已经实现了,那就尝试点不一样的,用 深度学习 解决一下。 基本思路基本流程类似,唯一的区别在于如何获取棋子和目标块的中心位置。 假如长按时间只取决于棋子和目标块的水平位置,那么只需要知道它们水平方向上的坐标即可。 可以看作一个 物体检测 问题,检测出截图中的棋子等物体,这里假设共包含七类物体:
模型实现我手动标注了500张截图,基于ssd_mobilenet_v1_coco模型和TensorFlow物体检测API,训练好的模型跑起来是这么个结果。
可以看到截图中的棋子、魔方、矩形块、圆形块都被检测了出来,每个检测结果包括三部分内容:
这不仅仅是简单的规则检测,而是 真正看到了截图中共有哪几个物体,以及每个物体分别是什么。 所以接下来,就只需从检测结果中取出棋子的位置,以及最上面一个非棋子物体,即目标块的位置。 有了物体的边界轮廓,取中点即可得到棋子和目标块的水平坐标,这里进行了归一化,即屏幕宽度为1,距离在0至1之间。然后将距离乘以一个系数,作为长按时间并模拟执行即可。 运行结果看起来很不错,实际跑分结果如何呢? 大概只能达到几百分,问题出在哪? 主要是标注数据太少,模型训练得不够充分,所以检测结果不够准确,有时候检测不出棋子和目标块,而一旦出现这类问题,分数必然就断了。 尝试了以下方法,将一张截图朝不同的方向平移,从而得到九张截图,希望提高检测结果的召回率,但仍然有检测不出来的情况,也许只有靠更多的标注数据才能解决这一问题。 规则检测模型训练了20W轮,依旧存在检测不出来的情况,郁闷得很,干脆也写一个基于规则的 简单版代码 好了。 花了不到20分钟写完代码,用OpenCV提取边缘,然后检测棋子和目标块的水平中心位置,结果看起来像这样。
事实证明,最后跑出来的分数,比之前的模型要高多了…… 说好的深度学习呢?
总结面对以下情况时,基于人工经验定义规则,比用深度学习训练模型要省力、有效很多:
当然,如果大家能一起努力,多弄些标注数据出来,说不定还有些希望。 代码在Github上:github.com/Honlan/wech… 不说了,我继续刷分去了,用后面写的不到一百行的代码…… |