WePY - 小程序敏捷开发实践丨掘金开发者大会
本主题虽然在其它地方讲了很多次,但还是有非常多新内容。因为很多东西正在做或者想要做。本次分享主要分为以下几个部分:

WePY 的介绍

WePY 的用户

上面展示的 WePY 用户不是全部的数据。因为没有办法让 WePY 用户主动上报自己在使用 WePY,所以我只列了我知道的在使用 WePY 的公司,数据比较有限。
就我所知道的,最近有一个刷爆朋友圈的小程序 —— 腾讯疫苗,前端采用的 WePY,后端用了腾讯开源的 TARS 项目。微信支付内部也有大量小程序在使用 WePY 框架。
右边贴的聊天记录是我在 WePY 交流群收集到的用户反馈,就反馈的内容来看,有很多感谢的话,说明 WePY 这个框架确实能帮助开发者提高自己的开发效率。嘿嘿,我没有贴 WePY 的负面反馈,因为我担心一页 PPT 不够贴 :eyes:。
WePY 的数据

WePY 项目在 Github 上现在有13900多个 Star。拿其它前端框架对比,Vue、React 等 Star 数可能达到了 10W+,但是它们都是国际的项目。WePY 这个项目由于微信小程序的原因,算是一个国内项目,能有13000多个 Star 还是相当不错的。Star 数多不一定代表 WePY 这个框架好,但是能表明小程序这块流量很大,开发小程序也非常有前景。 开发者们需要 WePY 这样的框架来提供帮助。这也是为什么后来出现了 Taro、mpvue 等类似的非常优秀的框架。
issues 目前有1300多个。这意味着我每天起床都有超过10条 to-do list 需要处理。加上每天还有公司的其它事情需要处理,比较头大。
pull requests 目前有320多条。相比其它开源项目,这个 PR 数量相当不错,非常感谢为 WePY 作贡献的开发者们。
用户数有4000多。这个数据的来源我是统计的我建立的 WePY 交流群,目前这个交流群里有 4000 多人。
WePY 是什么
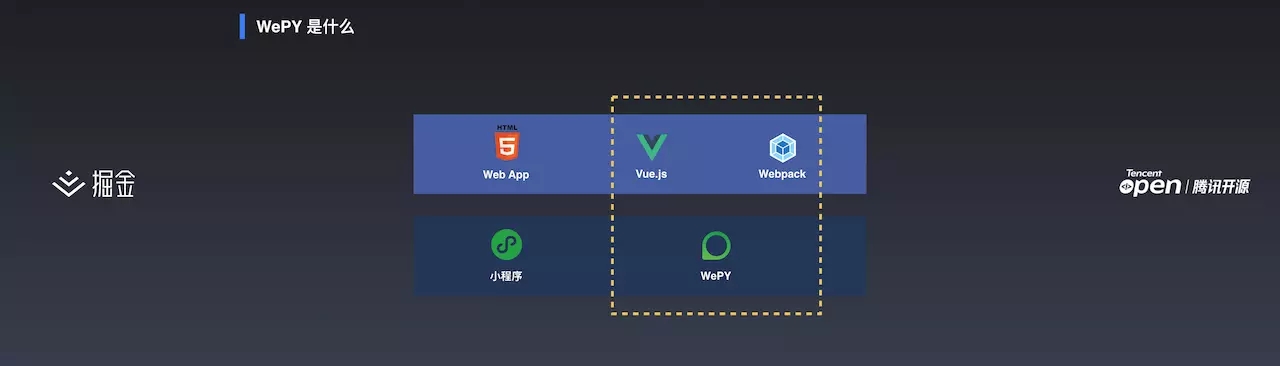
将 Web App 和小程序进行对比。Web App 和小程序在功能上类似, Web App 在开发的时候,可能使用 Vue.js 作为其核心库,用 Webpack 进行打包。在微信小程序中,大家可以简单的将 WePY 理解为 Web App 里的 Vue.js + Webpack 的合体。
WePY 的特点
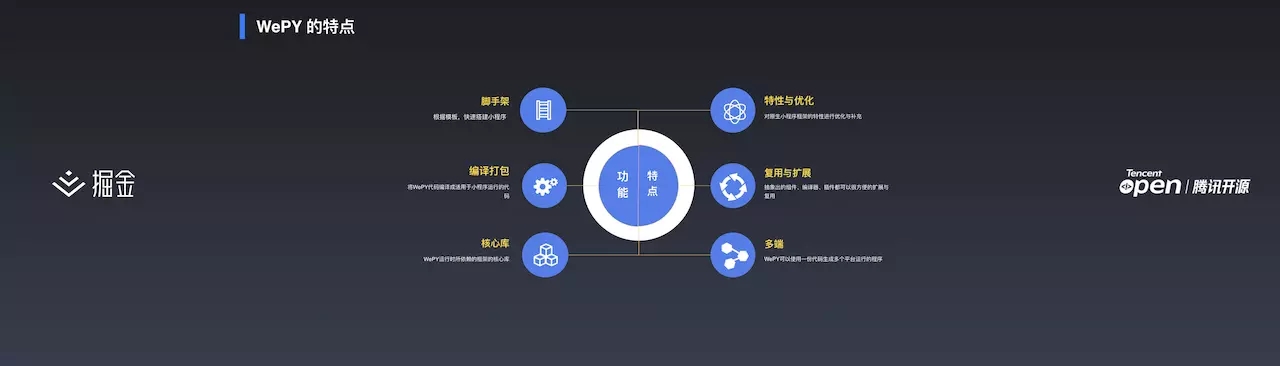
WePY 在开发中到底帮助开发者做了什么事情呢?WePY 又有哪些特点呢?
- 脚手架:它提供了一个相当于 vue-cli 的脚手架,一行命令生成简单的 demo 项目。用户可以基于这个 demo 进行开发,省去了启动项目前繁琐的配置。
- 编译打包:原生开发小程序缺失了许多能力,比如 LESS、SASS。很多用户面对这个问题都是做一个简单的 Gulp 编译。WePY 自带了编译打包能力,想用 LESS、SASS、NPM 等可以直接使用 WePY 的打包工具输出小程序可以运行的代码。
- 核心库:核心库类似 Vue、React 等。WePY 核心库包含一些简单的 API 封装帮助处理一些事情。
- 特性与优化:开发上,WePY 提供了一些语法糖,可以简单方便的实现一些复杂功能。性能上,小程序本身的性能有一些问题,WePY 把性能上的问题抹平了,开发者不用关心性能这部分。
- 复用与扩展:复用方面,原生小程序使用 npm 资源需要将相对应的资源下载并放到代码目录中,利用 WePY 可以直接安装 npm 包并使用。扩展方面,在编译过程中,可以随意添加和扩展编译手段,比如 LESS、SASS、编译插件等。
- 多端:利用 WePY 可以将一份代码运行在小程序、H5 等端。
WePY 的规划
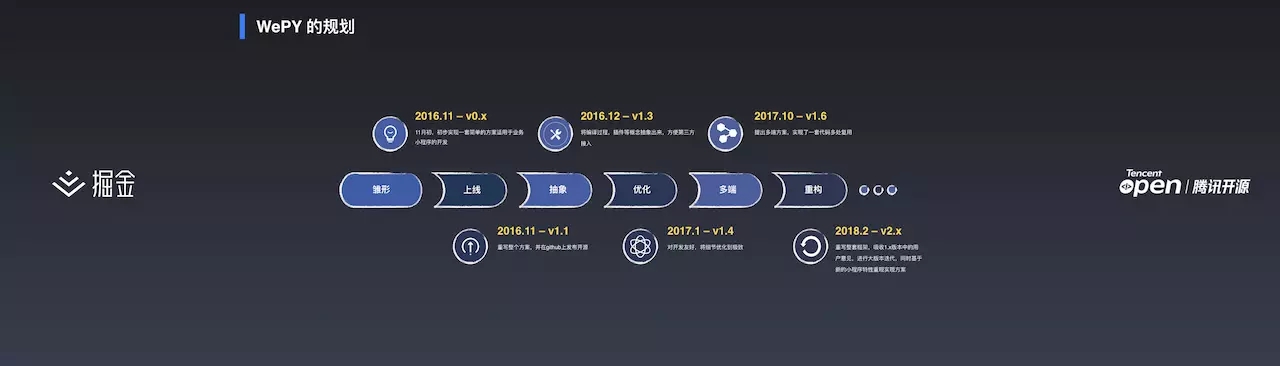
16年8月参加小程序内测,10月份开始着手代码转换相关的工作。在不停的迭代中,我发现还有很多事情可以做。比如可以将相关的工作抽象出来提供给其它开发者。于是在11月我对代码进行了重构,将 Gulp 编译部分抛弃重写并于 Github 开源1.1版本。
开源之后有很多人关注到这个项目,说明还是有不少人遇到了相应的问题。因此我做了更加具体的优化,在1.1版本上又一次重构,把编译流程抽象,提出了编译器和插件两个概念,方便用户进行扩展。
17年1月份发布1.4版本,对整个开发流程和开发者使用框架时的体验进行了更多优化,包括性能优化等。
1.6 版本开始考虑多端问题:小程序一套代码多端复用。
17年11月左右,小程序推出了原生组件。WePY 本身就是为了解决小程序组件的问题,原生组件发布之后,WePY 的使用场景就没有以前那么强了,所以我开始思考, WePY 需要做一个完全重构的版本。
18年2月份启动了该重构版本,这个版本主要是为了解决小程序原生组件相关的问题,是一个全新的重构版本。但由于各种原因,这个版本还没有正式公布。敬请期待!
WePY 的实现原理

接下来我会讲一下 WePY 在技术上的实现原理。
WePY 解决的问题
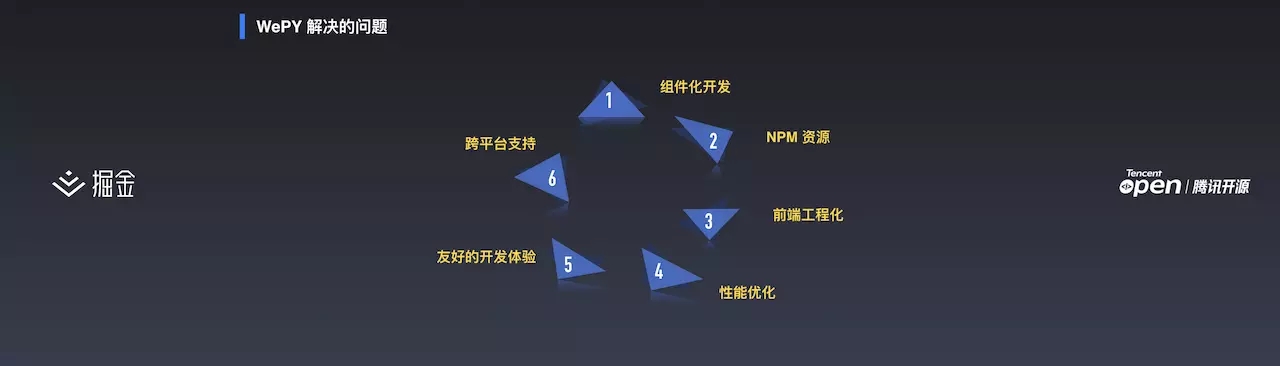
任何一个项目都是发现问题,解决问题的过程,WePY 要解决的问题就是:
- 组件化开发:小程序原生组件出现之前,小程序没有很好的组件化开发模式。比如我自己实现了一套 dialog,别人想使用的时候可能要把我的代码拷贝一份。实现了组件化之后,我只要把这个组件给他就好了。
- npm 资源:Web 发展至今,npm 库上有非常庞大的资源。但是原生小程序没有使用 npm 资源的能力,WePY 提供了这个功能。
- 前端工程化:前面提及的打包构建部分
- 性能优化
- 友好的开发体验:体验优化
- 跨平台支持:多端这部分
总的来说,WePY 解决的问题就是开发中遇到的痛点问题。
WePY 的架构
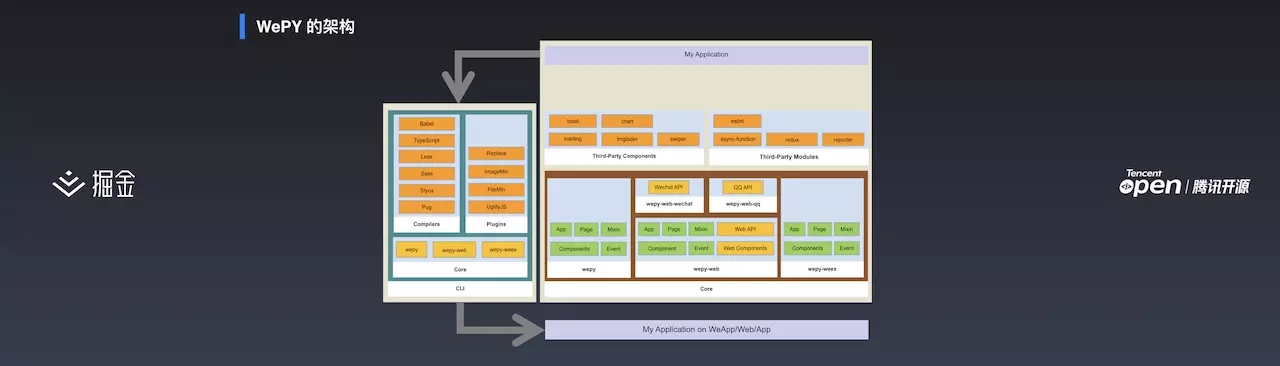
上面是我写的两个核心的部分:CLI 以及 Core。Core 通过 CLI 编译,生成小程序端运行的代码。CLI 部分又分为 wepy、wepy-web ,分别负责 wepy 的编译和 wepy-web 的编译。其上又分为编译器和插件两部分,编译器涉及到目前主流的预处理器,类似 Webpack 的 loader 。插件是在编译之后要做的事情,类似于 Webpack 的 plugin。Core 部分分为 wepy 核心库、小程序核心库和 wepy-web 核心库。wepy-web 核心库比小程序多了 wepy components 和 wepy API 。小程序本身的一些内置组件,比如弹窗组件,想要多端运行都需要封装起来放在 wepy components 。小程序原生 API 需要通过 wepy API 封装。
web 本身还分很多平台种类,比如 browser、微信 h5、QQ h5,这些都需要分别适配,所以 wepy-web 之上是一个适配层。
整个 Core 之上,是用户封装的一些组件,比如上报、异步。还有一些功能组件,比如用户做的弹窗、toast、imageloader 等。
纵观整个 WePY,我的代码会通过 CLI 基于 Core 输出小程序端运行的代码。
WePY 的编译过程
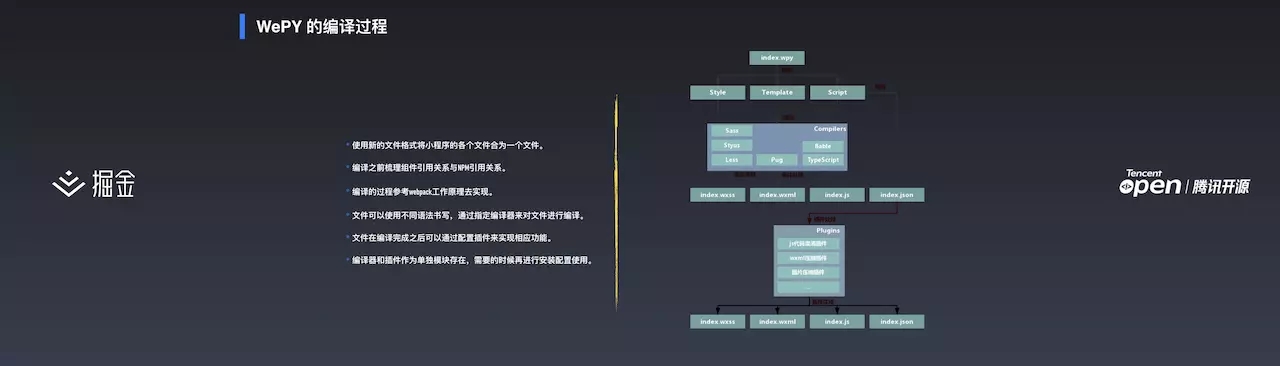
WePY 本身定义了一个文件后缀 .wpy 。编译时将该文件解析并拆分为 Style、Template、Script。拆分时,会解析并记录组件关系,包括事件、引用等。每个节点的信息都会被记录,在注入时生成到 JS 中,在 JS 中就可以知道组件关系并进行调用。生成完之后进入到 plugin,plugin 是用户自定义的,需要进行图片压缩、JS 混淆、wxml 压缩等处理。依次做完这些处理之后才会得到可以在小程序中运行的代码。
以上就是 WePY 的整个编译过程。
多端的实现
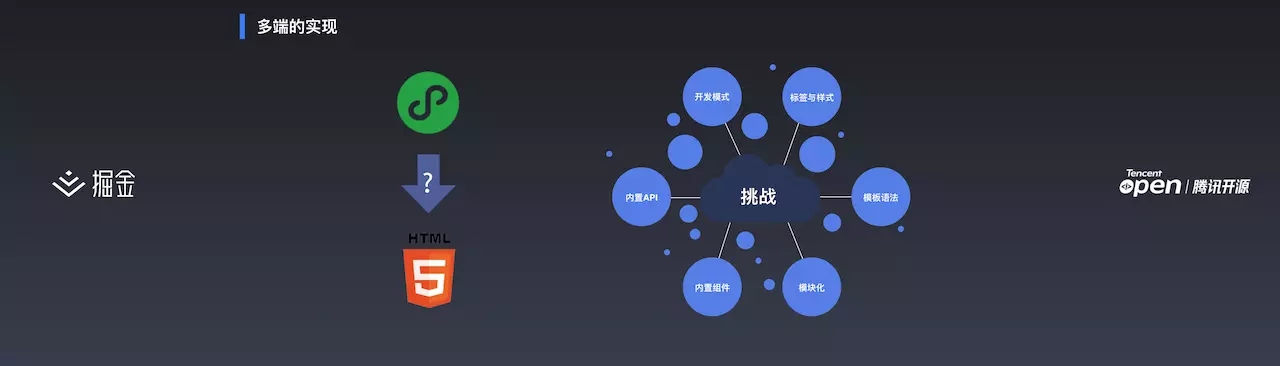
在实现多端方面,面临着以下问题:
-
开发模式
小程序开发模式自成一派,与现有开发模式都不相同。好在使用 WePY 开发时,WePY 使用的是类 Vue 的开发语法,跟 Vue 开发模式很贴近,所以开发模式问题借助 WePY 非常好解决。
-
标签与样式
小程序与 H5 的标签不一样,但是可以直接做一些简单的转换处理。比如 <view> 转换为 <div> 。样式上小程序有一个 rpx 单位,在 750 px 的情况下直接 /2 将 rpx 转为 px。
-
模版语法
小程序有自己的模版语法,比如 <wx-if> 等,解析时可以做简单的转换。
-
模块化
小程序原生可以使用 require ,但是H5不可以。好在有很多工具值得借鉴,比如 webpack,browserify。
-
内置组件及内置 API
WePY 本身使用的是类 Vue 的语法,要转换为 Vue 运行在 Web 端的话,内置组件直接使用 Vue 的形式编写,使用时直接引入这个 Vue 组件。内置 API 使用 WePY 提供的 JSSDK 去模拟微信端、H5等提供的 API。
因此,多端实现完全可行。我们的一些项目完全利用 WePY 实现多端。
生态
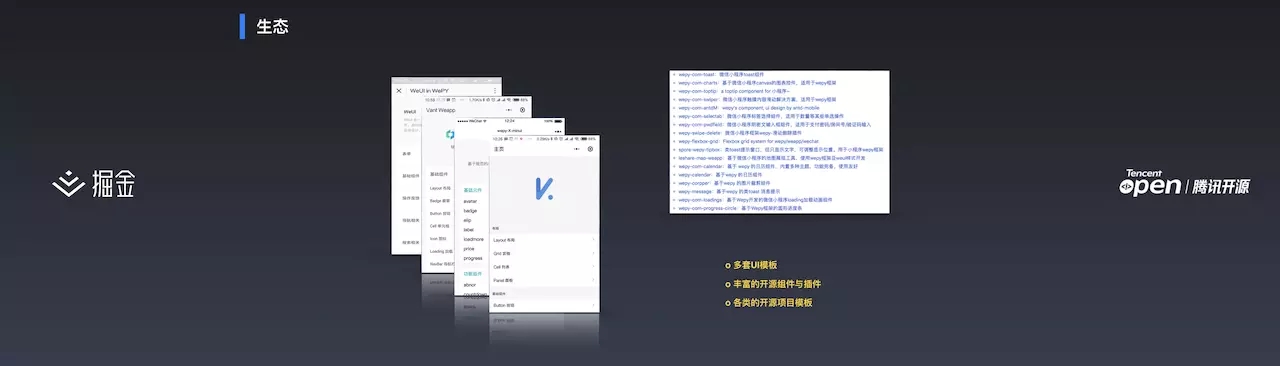
左边是在 Github 上看到的一些 UI 库,大家在使用 WePY 开发的时候可以直接利用这些 UI 库进行二次开发。右边是网上收集到的开发资源,包括开发组件、第三方模块等。Github 上 WePY 关键字搜索结果有900多页。从用户反馈来看,用户选择 WePY 的一个原因也是 WePY 诞生的时间长,生态比较完善。
WePY 的规划

现有问题
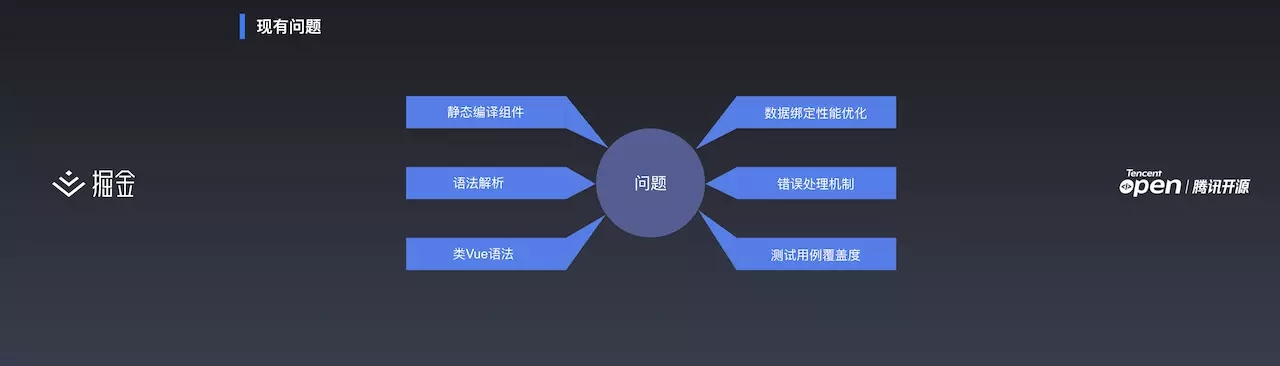
WePY 目前存在的核心问题是
-
静态组件编译
WePY 项目做的比较仓促,花了大概一个多月就上线了。最开始只是为了解决组件化的问题。因此它采用了静态组件编译这套方案,在编译组件时,直接将我写的组件进行静态替换,将我写的组件注入到页面中,做了一些隔离相关的事情。这导致动态 repeat 时会出现比较严重的 BUG。这是设计上的缺陷,也是急需解决的问题。
-
语法解析
xml 的解析用了一个存在问题的库,导致 xml 解析时经常出错。js 的解析设计之初没有考虑用语法树解析,而是使用正则进行解析。因为目前仅涉及解析和语法注入,实现起来都比较简单,所以没有考虑用 AST 语法树进行解析,导致用户没有按照规范写的一些代码在解析时会出现错误。
-
类 Vue 语法
从用户的反馈来看,大家更希望用 Vue 的语法而不是类 Vue 语法。这两个之间还是有一些差异的。
-
数据绑定性能优化
数据绑定时做了一些优化和处理。但这些优化和处理是通过脏数据进行的,帮助用户减少 setDate 的次数。但是后来再看,这块还是有可以优化的空间。
-
错误处理机制
目前 WePY 的错误处理还比较简单,没有一个通用的错误处理机制。用户在使用和编译时的报错很难追溯和定位。后面希望能做到在报错时可以定位到报错的文件和代码。
-
测试用例覆盖度
WePY 目前只有核心库被测试用例覆盖。CLI 部分很复杂没有做测试用例覆盖。这导致目前大部分问题都和 CLI 相关。在下一个版本要全部被测试用例覆盖。
编译
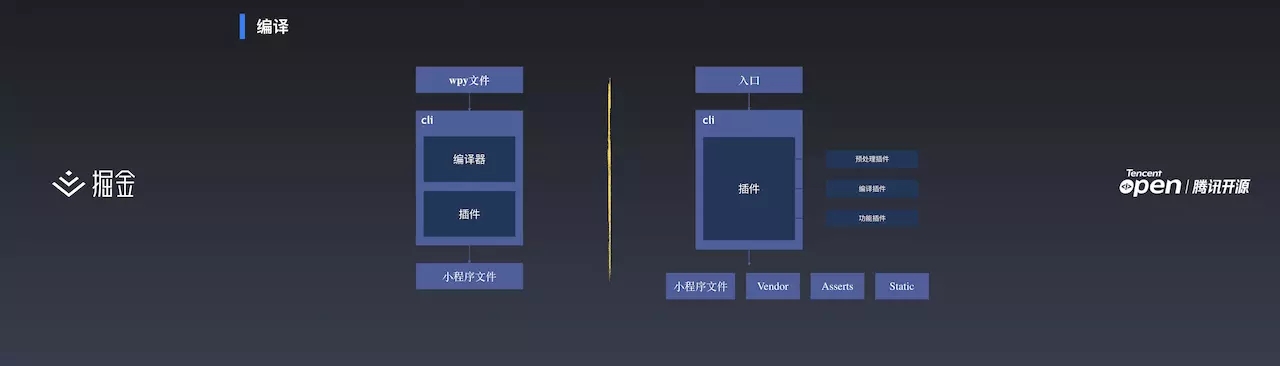
上图是2.0版本编译部分的对比。左边是 1.0 的编译,右边是2.0正在做的事。前面有讲到1.0的编译是把.wpy 文件放到 CLI 中进行编译。CLI 本身涉及编译器和插件。在2.0中,将文件编译修改为了入口编译,从 App 入口,通过 CLI 自动解析依赖,CLI 中也只有插件,所有的核心功能都将通过插件实现。最后生成的除了小程序文件,还有 Vendor 文件(Vendor 文件是指所有的 npm 包都会打包到这个文件内)、资源文件以及自己引用的模块的文件。
插件化

编译的核心部分是参考 Webpack 做的插件化编译。插件化的概念参考我上面做的图:固定一块板子,板子上有固定数量的挂钩,每个挂钩都可以挂不同的东西。每个挂钩放什么不清楚,但是每个挂钩都可以实现不同的功能。我只需要规定编译的流程,通过在挂钩中写不同的内容实现整个编译流程。所以整个编译过程变为:配置初始化:arrow_right:核心编译:arrow_right:输出文件。
插件化可以提供更高的扩展性和可复用性。所有的核心功能都依赖插件进行。用户觉得某个功能不合适的时候,完全可以自己写一个插件替换掉核心功能。用户可以对编译的任何一个环节进行修改。
数据绑定v1
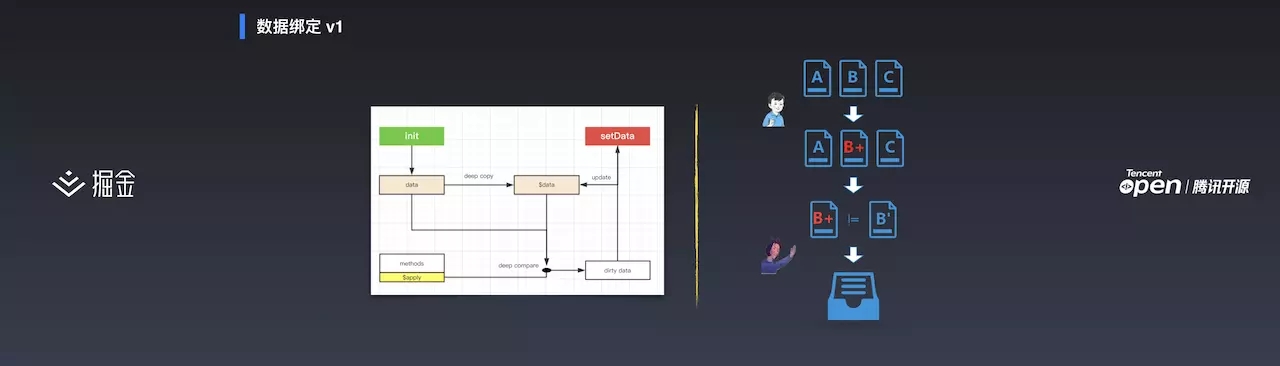
v1 的数据绑定:在初始化的时候对数据进行深拷贝做数据备份。每个流程都会预置 apply 动作,比如有一个点击事件,点击事件对数据进行修改后进入到 apply 流程,在 apply 流程中进行深比较得到脏数据,脏数据最终进入到 setDate 中。
右边是比较简单易懂的图:小明对文件 B 进行修改得到 B+,老师将 B+ 和 B 进行对比,得到修改的数据。这是一个同步流程。当小明叫小红修改 C 文件时,如果老师不再,需要小红主动叫老师对 C 文件进行对比。即手动调用 apply 流程。
数据绑定v2
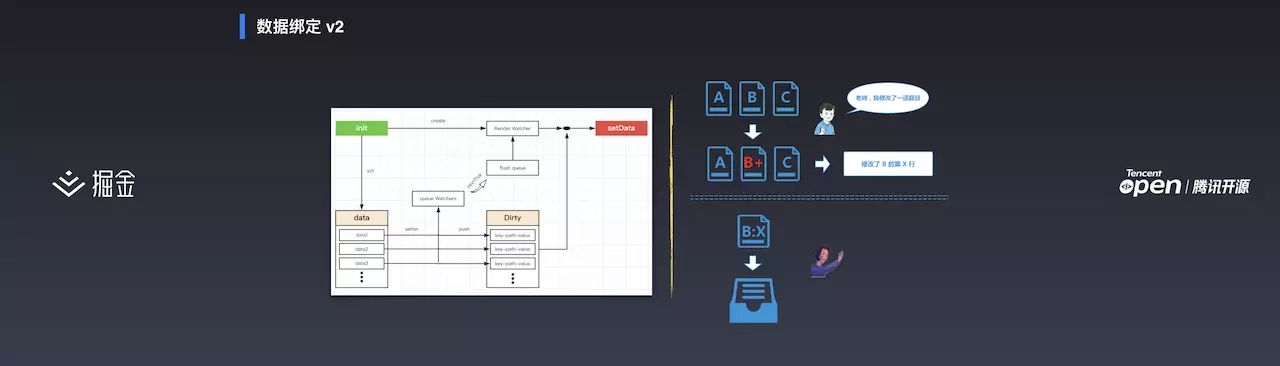
2.0 使用了 Vue 的数据绑定机制。在初始化时生成 Render Watcher,每个数据初始化时都会添加 observer。修改数据时记录修改的 key-path 并加入队列中,所有的修改动作都会触发 Watcher。在一个 nextTick 时间内会清空队列,并在 Render Watcher 中进行 setDate。setDate 环节根据记录的 key-path 进行 setDate。
相比小明和老师的故事:小明在修改文件时会主动记录修改的内容并发起通知,小红的操作方式与小明一致。当老师收到通知时,根据小明、小红的修改记录对修改的内容进行 setDate 的处理。
这种优化方式不需要手动调用 apply,也不需要关心异步流程。
质量

第二个版本会先在内部项目运用,内部实践之后没有问题再开源。另外2.0版本测试用例覆盖度要完全覆盖。
开源经验分享

规范

如何保证开源项目的质量?
第一是文档规范。Readme 部分要言简意赅的讲明这个项目能做什么,一个简单的示例说明如何启动项目。Readme 要简洁,大家一眼能看到他想要的东西。
第二是 CI。将对应的状态放在 Readme,让开发者可以更安心的使用这个项目。
第三是 license。
还有 contributer 文档,代码规范、Git 规范等。
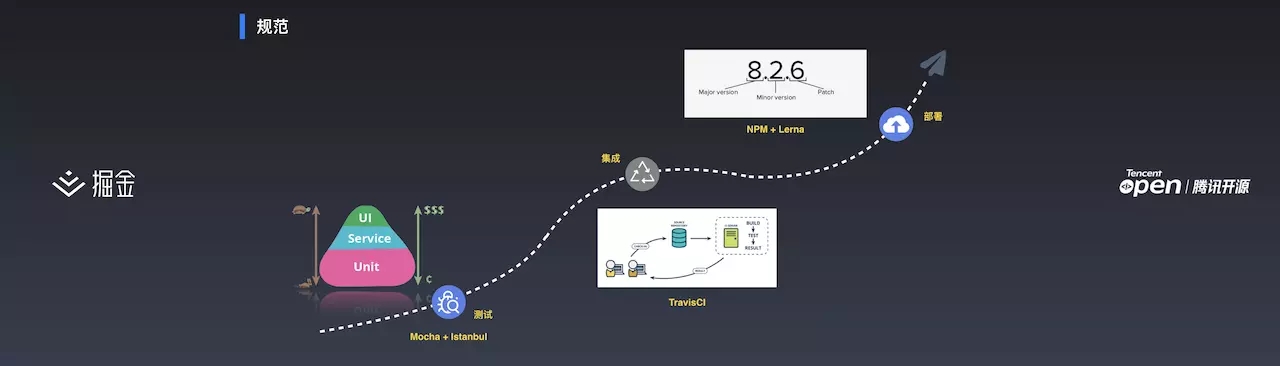
测试使用了 Mocha 和 Istanbul,集成使用了 TravisCI,部署使用了 npm 和 lerna。
推广运营
推广运营方面主要靠自己发文章,做外链。另外我在公众号和微信群推了自己的文章。微信群做了一个机器人放入群码。
还做了文档监控,官方文档修改之后,我可以第一时间知道官方文档都修改了什么。以及监控报告,每天都会给我的微信推送今天项目有多少 star 、多少 issue 。



